














1、训练侧:GPT3.5对应数千张H100,多模态需求再提升数倍至十倍。
GPT3.5同级别模型约需要数千张H100进行训练。根据GPU Utils报道,Inflection表示,针对他们与GPT3.5相当的大语言模型,其使用了大约3500张H100进行训练。2)同时,对于初创公司而言,其需要数千张H100对大语言模型进行训练,需要几十张或者小几百张H100做微调。
考虑H100价格约为3-4万美元/张,对用算力投入约为近亿美元。根据快科技报道,H100价格约合人民币24万元,对应3-4万美元/张。考虑以Inflection为代表的公司算力投入在3500张级别,对应总投入或约为近亿美元。
GPT4或对应数万张A100,GPT5或对应数万张H100。1)根据GPU Utils报道,GPT4有可能是在10000-25000张A100上训练的。而对于GPT5,其可能需要25000-50000张H100进行训练。2)相比GPT3.5约数千张H100的需求量,GPT4、GPT5等相对成熟的多模态模型算力需求提升约数倍至十倍级别。
2、推理侧:仅考虑文字问答场景,需要数万张H100,多模态提升空间广阔。
1)每日访问量:6000万。
2023年6月6日,根据科创板日报报道,据SimilarWeb最新数据,2023年4月OpenAI网站访问次数已达到18亿次,则对应每日访问量约为6000万次。
2)用户平均访问时长:5分钟。
根据科创板日报报道,每次访问时长约为5分21秒。
3)单个token输出需要的时间:62.5ms;每秒生成token数量:16个。
根据百度智能云的部分案例,在Batch Size为1时,输出8个token大约需要353ms;在Batch Size增加到16时,输出8个token大约需要833ms。则输出8个token的时间中值约为500ms(即0.5秒),即单个token所需要的计算时间约为62.5ms(即0.0625秒),对应每秒生成token数量约为16个。
4)平均实时并发:333.33万个token/s。
6000万*(5*60)s*16token/s/(24*60*60)s=333.33万个token/s。
5)算力利用率:20%。
Transformer为自回归模型,这意味着在原始状态下,每生成1个新token,都需要将所有输入过的token再次计算。
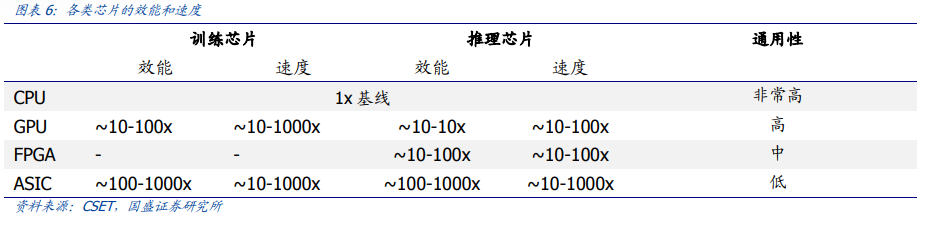
根据百度智能云技术研究,以175B的GPT-3模型,输入1000个token,生成250个token为例:
•Context(即Encoder)阶段的激活Shape为[B,1000,12288],其中B为batch_size,第二维为输入token数,第三位为hidden size。
•而对于Generation(Decoder)阶段,由于每次输入输出都是固定的1个token,是通过循环多次来产生多个输出token,所以Generation阶段的激活Shape的第二维始终为1,Generation的激活显存占用是远小于Context阶段的。
由此导致,Context 是计算密集型的任务,而 Generation 是访存密集型的任务。这也意味着,在推理阶段,硬件的算力利用率由于受到显存带宽等的限制,会显著较低。

根据百度智能云报道,一般情况下,在线服务的GPU使用率不高,在20%左右。另外,若部署其用户态方案,保证在线服务的SLA相同的情况下,可以将GPU资源利用率提升至35%。
6)峰值倍数:10倍
推理服务一个典型的负载模式是一天中峰谷波动明显,且会出现不可预期的短时间流量激增。根据百度智能云统计,我们假设峰值倍数约为10倍。
7)所需算力总量:5.83*10^19FLOPS。
2*1750亿个参数*333.33万个token/s*10倍/20%算力利用率=5.83*10^19FLOPS。
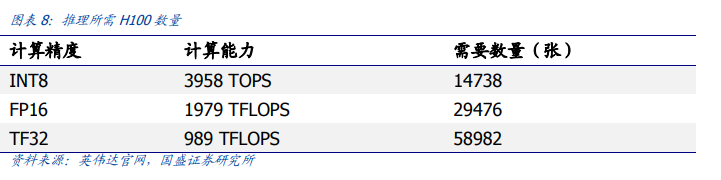
8)所需H100数量:1.5-6万张。
根据英伟达官网,H100 SXM INT8、FP16、TF32对应的计算能力分别为3958TOPS、1979TFLOPS、989TFLOPS。则分别对应H100数量约为1.47、2.95、5.90万张。
我们认为,目前应用较为广泛的文字交互仅为Chatgpt以及AIGC应用形式的开端,语音、图片、视频等多模态的输入输出,或将为内容创作领域带来革命性变化。
而更广的数据形态、更多的应用场景、更深的用户体验,亦将大幅提升支撑人工智能的算力需求。英伟达进军ASIC,为推理阶段的算力需求未雨绸缪,算力或迎来高速扩张时代。

 公安备案号 51010802001128号
公安备案号 51010802001128号