












-
机器人模型新进展 RT2
东方狙击 / 2023-08-30 21:30 发布
小熊跑的快 2023-08-30 15:48 发表于美国
按照海外的产业预测,机器人25年有重要重要落地,24年底 自动驾驶L3舱驾一体量产,25年看到销量变化(英伟达,高通,特斯拉的业绩可以验证了)。
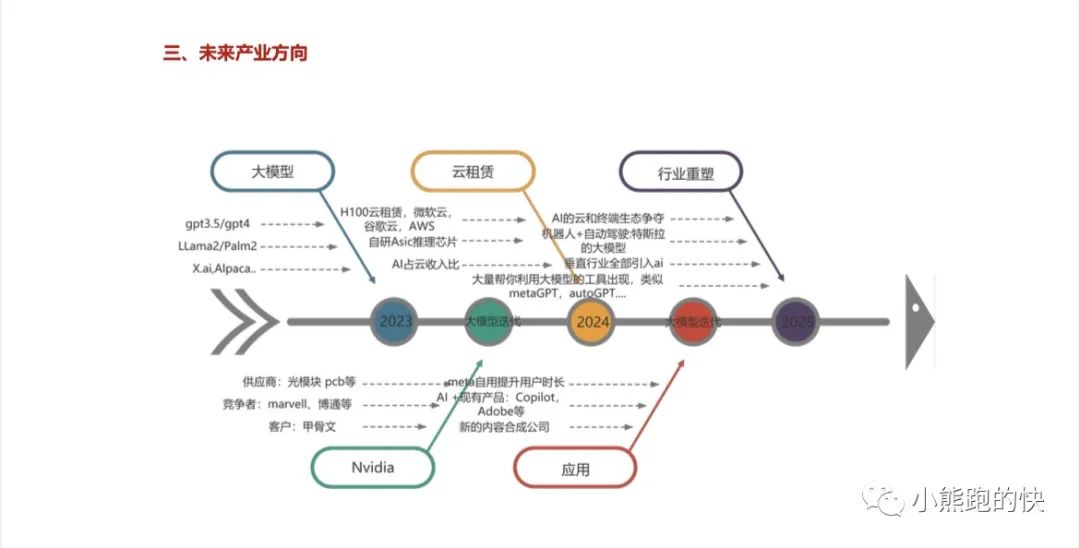
数据来源:国信研究所报告
但最近google 出了一些 刺激!大家可以看看。
最近是RT2,讨论比较多!这是google最新进展!
从语言到视觉+语言,现在进化到视觉+语言+动作(VLA模型)!
google团队研究如何将在互联网规模数据上训练的视觉语言模型直接纳入端到端机器人控制中,以促进泛化并实现紧急语义推理。我们的目标是使单个端到端训练模型能够学习将机器人观察映射到动作,并享受对来自网络的语言和视觉语言数据进行大规模预训练的好处。为此,我们建议在机器人轨迹数据和互联网规模的视觉语言任务(例如视觉问答)上共同微调最先进的视觉语言模型。与其他方法相比,我们提出了一个简单、通用的方法来实现这一目标:为了使自然语言响应和机器人动作符合相同的格式,我们将动作表示为文本标记并将它们直接合并到训练集中该模型的方式与自然语言标记相同。我们将此类模型称为视觉-语言-动作模型(VLA),并实例化此类模型的一个示例,我们将其称为 RT-2。我们广泛的评估(6000 次评估试验)表明,我们的方法可以产生高性能的机器人策略,并使 RT-2 能够从互联网规模的训练中获得一系列新兴能力。这包括显着改进对新物体的泛化能力、解释机器人训练数据中不存在的命令的能力(例如将物体放置到特定数字或图标上)以及响应用户命令执行基本推理的能力(例如拾取最小或最大的物体,或者最接近另一个物体的物体)。我们进一步表明,结合思维推理链允许 RT-2 执行多阶段语义推理,例如找出要拿起哪个物体用作临时锤子(石头)。
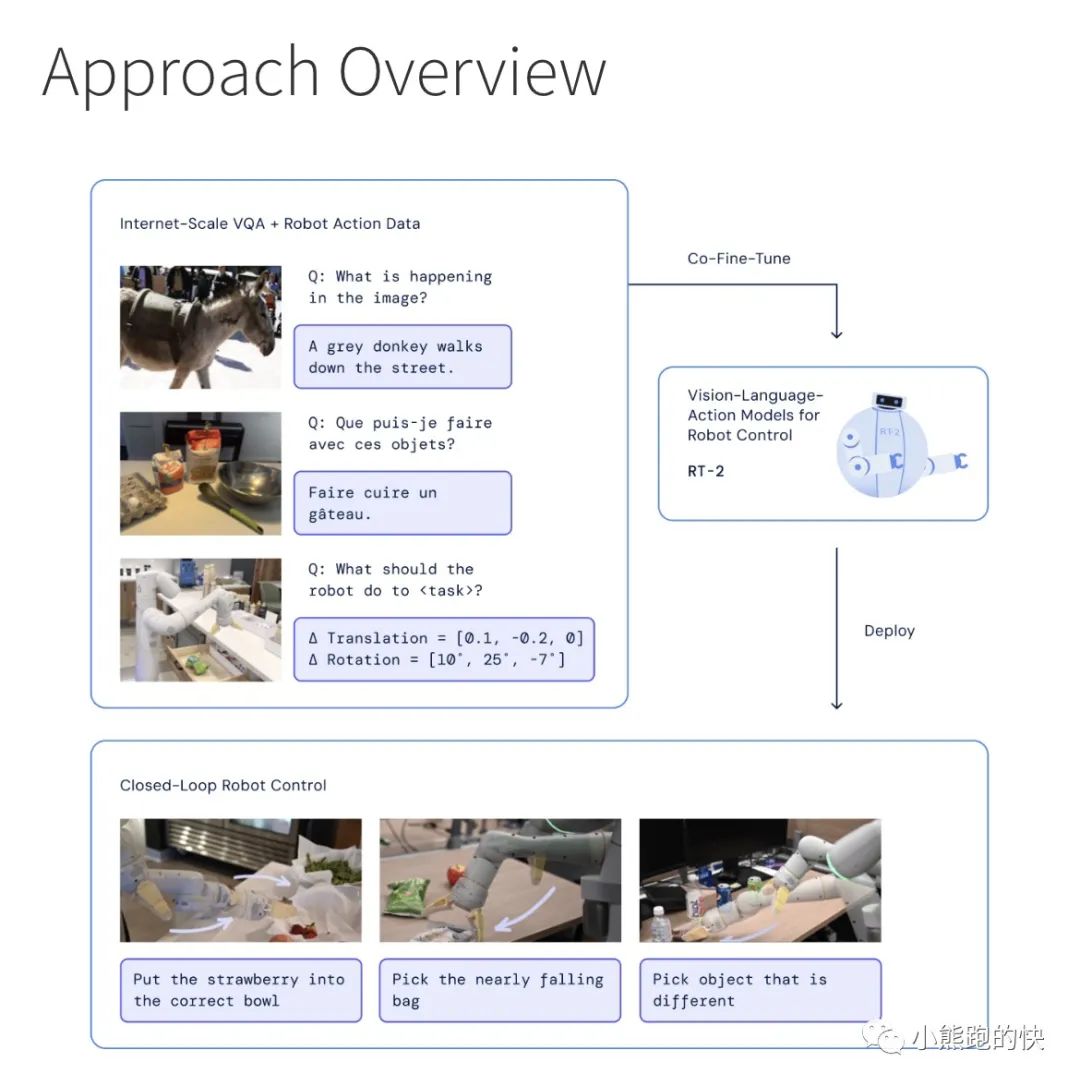
为了使 RT-2 轻松兼容大型预训练视觉语言模型,我们的方法很简单:我们将机器人动作表示为另一种语言,可以将其转换为文本标记并与互联网规模的视觉语言数据集一起训练。特别是,我们对现有的视觉语言模型与机器人数据进行协同微调(微调和协同训练的结合,其中我们保留一些旧的视觉和文本数据)。机器人数据包括当前图像、语言命令和特定时间步的机器人动作。我们将机器人动作表示为文本字符串,如下所示。此类字符串的示例可以是机器人动作标记编号的序列:“1 128 91 241 5 101 127 217”。

由于动作被表示为文本字符串,因此我们可以将它们视为另一种允许我们操作机器人的语言。这种简单的表示使得可以直接微调任何现有的视觉语言模型并将其转变为视觉语言动作模型
在推理过程中,文本标记被去标记为机器人动作,从而实现闭环控制。这使我们能够利用视觉语言模型的骨干和预训练来学习机器人策略,将其一些泛化、语义理解和推理转移到机器人控制中。这一举措拥有划时代的意义!解决数据源格式不通的问题。
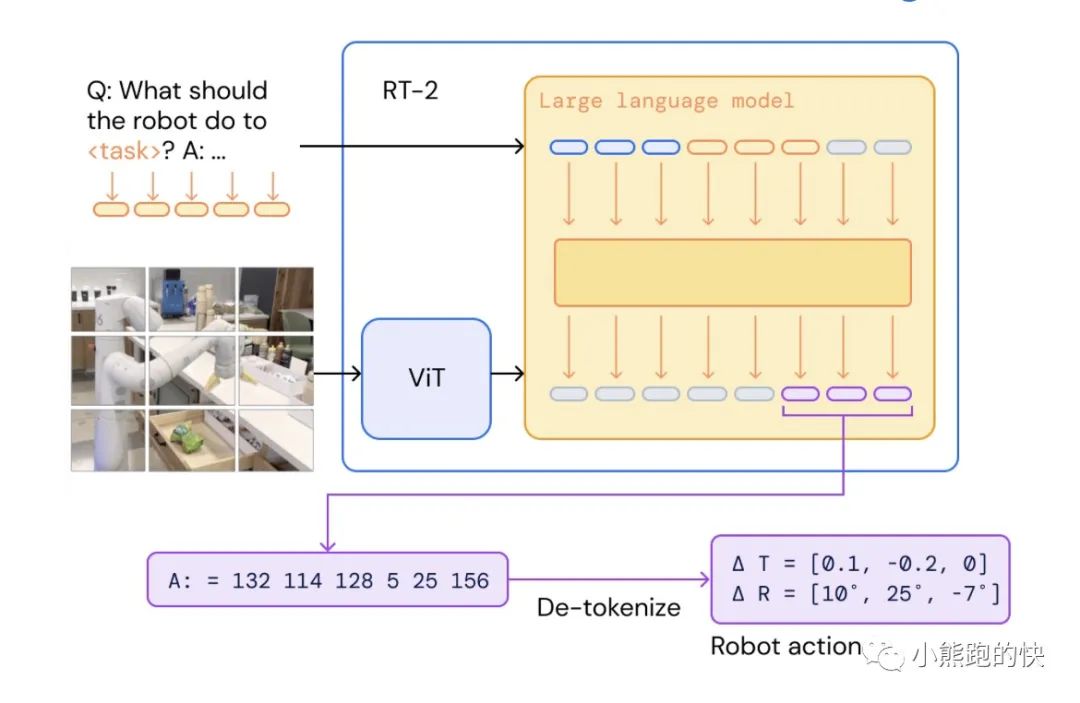
测试结果:
我们从测试模型的涌现属性开始评估 RT-2。由于我们无法完全预测 RT-2 泛化的扩展,因此我们向机器人展示了许多以前未见过的物体,并评估其在需要语义理解的任务上的性能,这些语义理解远远超出了模型微调的机器人数据在。您可以在下面看到我们发现令人惊讶的成功任务的定性示例:

为了量化 RT-2 的新兴特性,我们将它们分类为:符号理解、推理和人类识别,并评估 RT-2 的两个变体:
RT-2 在 PaLM-E(12B 参数)之上进行训练,
RT-2 在 PaLI-X 之上进行训练(55B 参数)
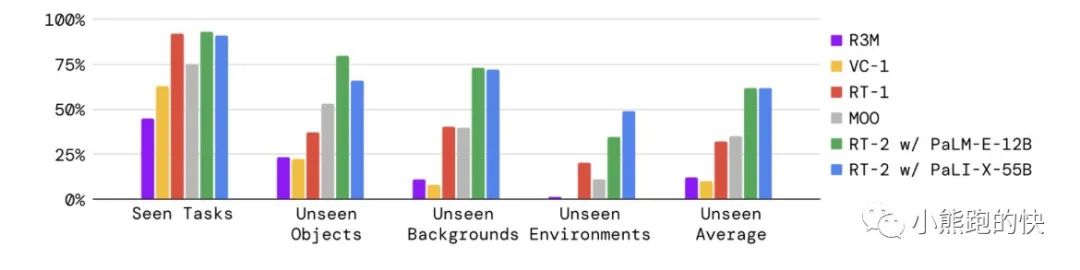
与其前身 RT-1 和另一种视觉预训练方法 VC-1 进行对比。下面的结果表明,与基线相比,RT-2 有了显着改善 (3 倍)。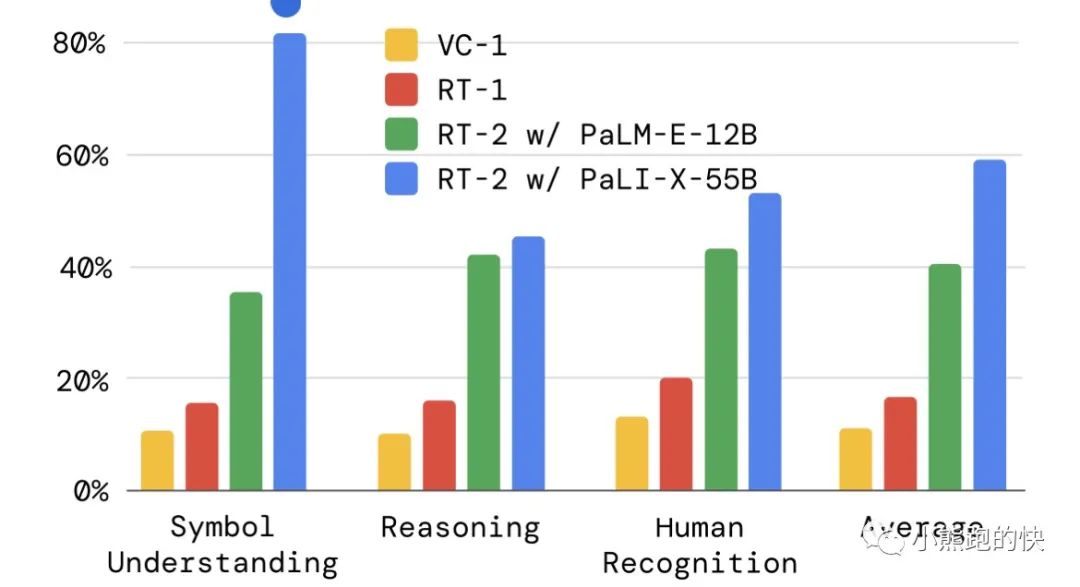
我们评估了 RT-2 的两种变体,以及盲 A/B 研究中的更多基线,并在下面的多个泛化轴上展示了结果。 RT-2 的泛化能力提高了大约 2 倍。
为了更好地理解 RT-2 的不同设计选择如何影响泛化结果,我们消除了两个最重要的设计决策:
模型尺寸:RT-2 PaLI-X 变体的 5B 与 55B,
训练秘诀:从头开始训练模型、微调、协同微调。
下面的结果表明了视觉语言模型预训练权重的重要性以及模型泛化能力随着模型大小而提高的趋势。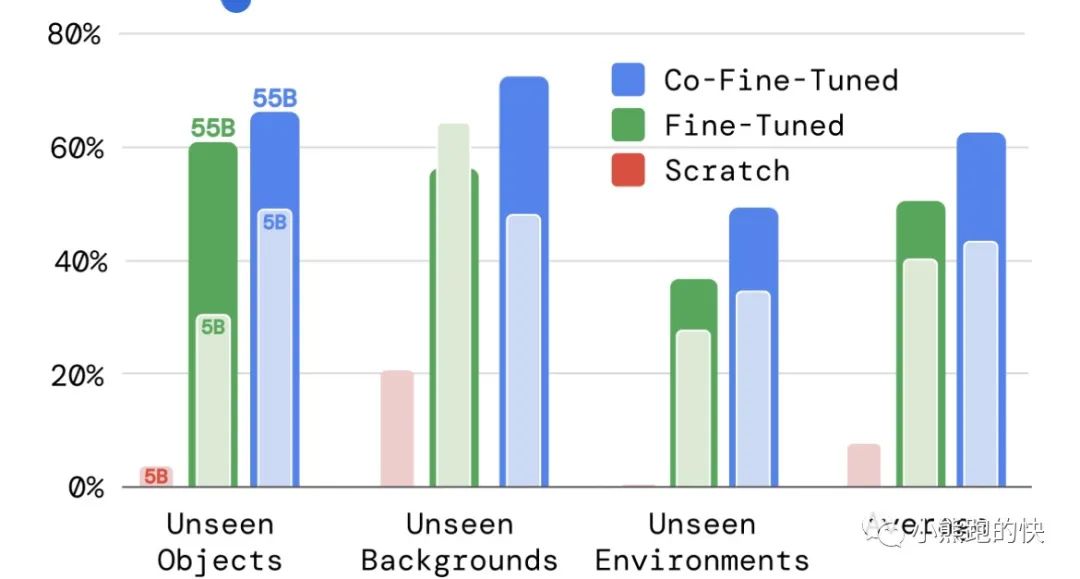
最后,由于所得模型的 RT-2 PaLM-E 版本是视觉-语言-动作模型,可以在单个神经网络中充当 LLM、VLM 和机器人控制器,因此我们证明 RT-2 可以执行控制的思想链推理。在下面的示例中,RT-2 首先以自然语言输出一些推理步骤,然后跟随字符串:“Action:”以及生成的操作标记。
这显示了完全集成的 VLA 模型的前景,它不仅可以跨不同模态迁移一些语义概念(例如,将机器人动作推广到新的语义类别),还可以迁移底层模型的一些属性(例如,思维链推理) )。

Demo:
展示了一些展示 RT-2 执行示例的视频。我们证明 RT-2 能够泛化到新对象、新环境和新任务。 RT-2 能够推广到各种需要推理、符号理解和人类识别的现实世界情况。
RT-2 可以表现出类似于视觉语言模型的思维链推理迹象。我们定性地观察到,具有思想链推理的 RT-2 能够回答更复杂的命令,因为它首先被赋予了用自然语言规划其动作的位置。这是一个很有前景的方向,它提供了一些初步证据,表明使用 LLM 或 VLM 作为规划器可以与单个 VLA 模型中的低级策略相结合。
海内外评述:
纽约时报:
一个单臂机器人站在一张桌子前。桌子上坐着三个塑料雕像:狮子、鲸鱼和恐龙。工程师给机器人发出指令:「捡起灭绝的动物。」机器人呼呼地响了一会儿,然后手臂伸出,爪子张开落下。它抓住了恐龙。
这是一道智能的闪光。
《纽约时报》描述道,「直到上周,这一演示还是不可能的。机器人无法可靠地操纵它们以前从未见过的物体,它们当然也无法实现从「灭绝的动物」到「塑料恐龙」的逻辑飞跃。」!
论坛:大模型为机器人 带来一道曙光!
解决数据的问题!
谷歌新的 RT-2 模型,全称为 Robotic Transformer 2,运用 Transformer 架构作为其模型的基座。
大语言模型中,语言被编码为向量,人们为模型提供大量的语料,使其能够预测出人类通常下一句会说什么,借此生成语言回答。
而在视觉语言模型中,模型可以将图像信息编码为与语言类似的向量,让模型既能「理解」文字,又能用相同方式「理解」图像。而研究员们为视觉语言模型提供大量的语料和图像,使其能够执行视觉问答、为图像添加字幕和物品识别等任务。
语言的数据量很多,网络抓取 购买都相对容易!所以大模型里面率先突破的就是NLP路径,紧接着图像+语言预计也会 很快有大的进步(一般意义上的双模态)!
但是机器人的数据非常昂贵(这也是四年前 openai放弃机器人模型的主要原因),
在谷歌研究的第一代机器人 Transformer 模型 RT-1 中,谷歌第一次开启了这样的挑战,尝试建立一个视觉语言动作模型。
为了建立这样的模型,谷歌使用了 13 个机器人,在一个搭建的厨房环境中耗时 17 个月收集到了机器人在 700 多个任务上的主动数据组建的数据集。(资料来源:极客公园)。
数据集同时记录了三个维度:
视觉——机器人在执行任务操作时的摄像头数据;
语言——用自然语言描述的任务文字;
和机器人动作——机器手进行任务时在 xyz 轴和偏转数据等。
虽然当时得到了较好的实验效果,但可想而知,想要进一步增加数据集内数据的数量,将是一件非常难的事情。
而 RT-2 的创新之处在于,RT-2 使用前面所述的视觉语言模型(VLM)PaLM-E 和另一个视觉语言模型 PaLI-X 作为其底座——单纯的视觉语言模型可以通过网络级的数据训练出来,因为数据量足够大,能够得到足够好的效果,而在微调(fine-tuning)阶段,再将机器人的动作数据加入进去一起微调(co-finetuning)。
这样,机器人相当于首先已经拥有了一个在海量数据上学习过了的常识系统——虽然还不会抓取香蕉,但是已经能够认识香蕉了,甚至也知道了香蕉是一种水果,猴子会比较喜欢吃。
而在微调阶段,通过再加入机器人在真实世界中看到香蕉后是如何抓取香蕉的知识,机器人就不但拥有了在各种光线和角度下识别香蕉的能力,也拥有了能够抓取香蕉的能力。
在这种方式下,用 Transformer 架构训练机器人所需的数据显著降低了。
RT-2 在微调阶段直接使用了 RT-1 训练阶段使用的视觉/语言/机器人动作数据集。谷歌给出的数据显示,在抓取训练数据中原来出现过的物品时,RT-2 的表现与 RT-1 同样好。而因为有了「拥有常识的大脑」,在抓取之前没有见过的物品时,成功率从 RT-1 的 32% 提升到了 62%。
这就是大模型的妙处!智慧涌现!

 公安备案号 51010802001128号
公安备案号 51010802001128号