












-
Deepseek是“算力屠夫”还是“新春红包”?
川川不息 / 01月29日 18:15 发布
Deepseek或是算力星辰大海的一朵“小浪花
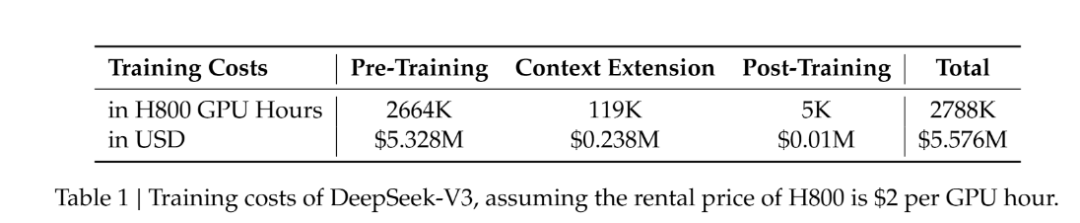
1. 556万美元远远低估DeepSeek v3真实训练算力与未来发展需求
据DeepSeek V3论文,556万美元的成本仅包括DeepSeek-V3 的正式训练,不包括与架构、算法、数据相关的前期研究、消融实验的成本。而基于充足前期准备进行正式训练的成本往往都比较低,单独讨论正式训练成本属于断章取义。以同样在2025年1月发布的加州大学伯克利Sky-T1-32B-Preview为例,其正式训练成本仅为450美元,但在数学能力等方面跑分超过OpenAI o1-Preview。

DeepSeeK V3论文:

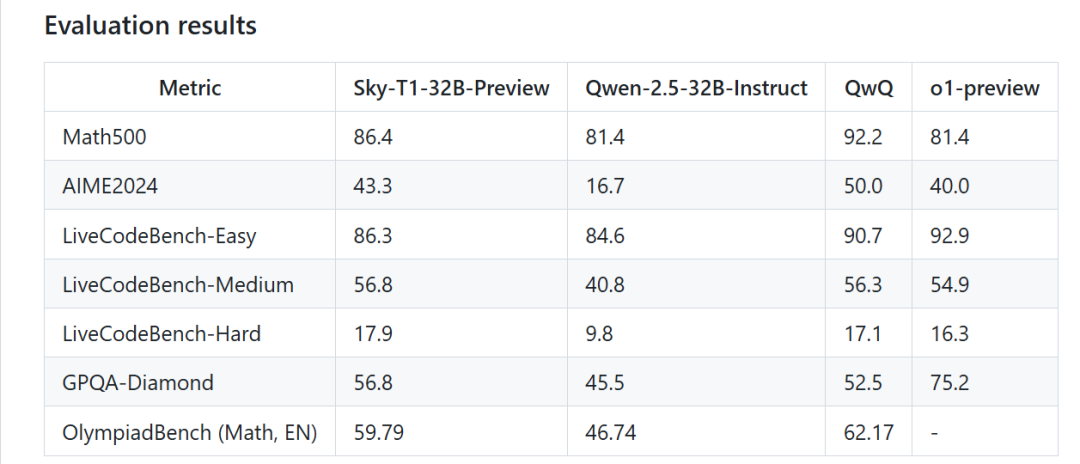
Sky-T1-32B项目地址:网页链接
2. 太阳底下无新鲜事:后发模型的算力效率优势曾导致英伟达股价大跌,事后看只是算力需求发展星辰大海的小浪花
无独有偶,2024年4月19日,Meta发布LLaMA 3大模型,从跑分数据来看70B参数的开源模型基本可与GPT4相媲美,引发了关于算力需求讨论,当日英伟达大跌10%。而伴随后续GPT4o、OpenAI o1等全新模型发布,训练算力需求仍在持续扩大,事实上LLaMA 3发布后英伟达大跌后成为一轮新行情的起点。DeepSeek大模型的发布,或带来更强的鲇鱼效应,OpenAI CEO奥特曼对于Deepseek作为竞争对手很兴奋,并宣布将加速发布更好的模型。
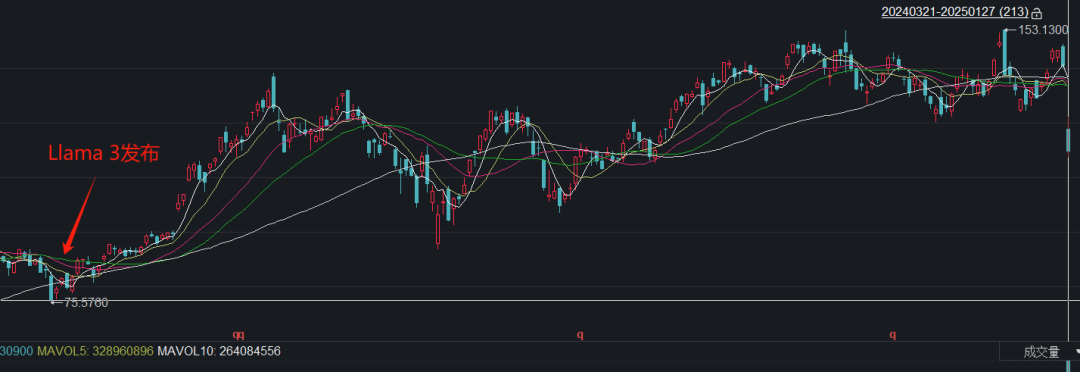
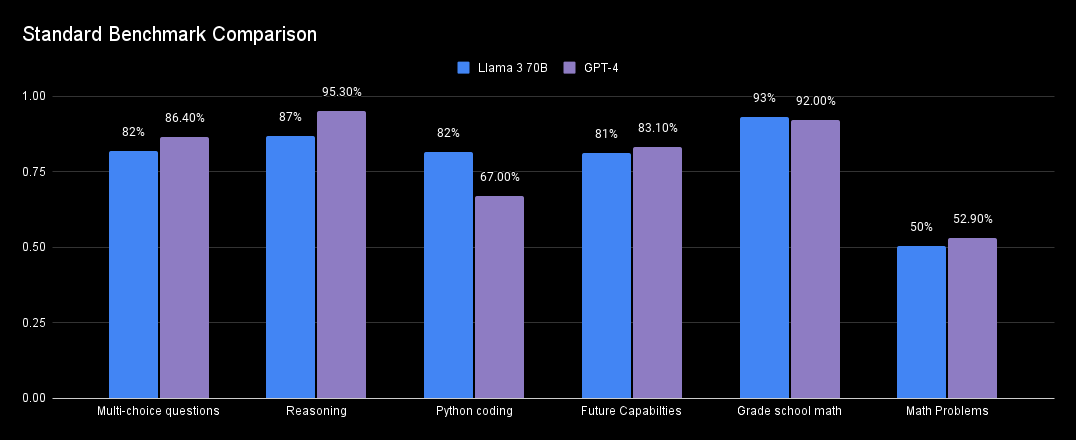 llama 3 VS GPT4:网页链接
llama 3 VS GPT4:网页链接3. Jevons 悖论:降低AI行业进入门槛与成本,反而推动总需求上升
DeepSeek所有模型均为开源模型,即所有应用厂商一夜之间都拥有了可以比肩顶级AI的大模型,而且还可自行二次开发、灵活部署,这将加速AI应用的发展进程。当模型的成本越低,开源模型发展越好,模型的部署、使用就会更高频率、更多数量。DeepSeek的突破让很多人第一次认识到AI模型的实用价值,真正开始使用模型。有了更多低成本、本地、开源模型,Token的需求量会成千上万倍的增加。这就是经济学上著名的“杰文斯悖论”:
“当技术进步提高了资源使用的效率,不仅没有减少这种资源的消耗,反而因为使用成本降低,刺激了更大的需求,最终导致资源使用总量反而上升。”
过去已经有很多的例子证明这点:
1、第一次工业革命期间蒸汽机效率的提高,使得市场上煤炭的消耗总量反而增加;
2、手机从大哥大年代到目前智能手机普及时代, 单价下降为十分之一左右,但手机市场放大数十倍。
3、如果一个家庭买了一台更节能的空调。按理说,更节能的空调应该会减少电费支出。但实际发生的往往是:因为电费便宜了,这家人反而更舍得开空调了,不仅开得时间更长,温度还调得更低,最后总电费不降反升。
模型算力效率突破,看起来影响单位计算的价格,进而压缩高性能芯片供应商的利润空间。但从更长的周期来看,恰恰会加速AI的普及和创新,带来算力需求更大量级提升。
蛇年开启,我们只要想清楚三个问题,DeepSeek造成的全球算力恐慌性抛售或是“新春红包”:
1、大模型架构演进是否到了尽头?DeepSeek R1反而说明架构演进创新正在持续,尤其在多模态、世界模型等领域,更多架构演进与创新正在进行;
2、大模型的性能目标是否已经达到?目前大模型距离AGI甚至ASI仍然有很长的路要走,强化学习本质上就是用算力完成数据自循环,需要更多更强的算力;
3、大模型的算力需求是否已经饱和?DeepSeek的目标是做开源的AGI,实现这一目标,降低大众获得AGI的门槛,无处不在训练与部署AGI的算力需求是我们今天所不可想象的,那是真正的“星辰大海”。
通往AGI之路仍然漫长,我们坚信像DeepSeek一样的玩家会越来越多,大家对中国AI产业的信心会越来越强,我们也将真正进入AI应用繁荣的起点。民生计算机

 公安备案号 51010802001128号
公安备案号 51010802001128号