












-
国产AI大模型:DeepSeek产业链全解析
糖芯儿 / 01月26日 21:55 发布
DeepSeek近一周来在全球科技圈持续刷屏。 1月20日,DeepSeek正式发布开源R1推理模型,性能上与世界顶尖的闭源模型OpenAIo1比肩,且成本更低。 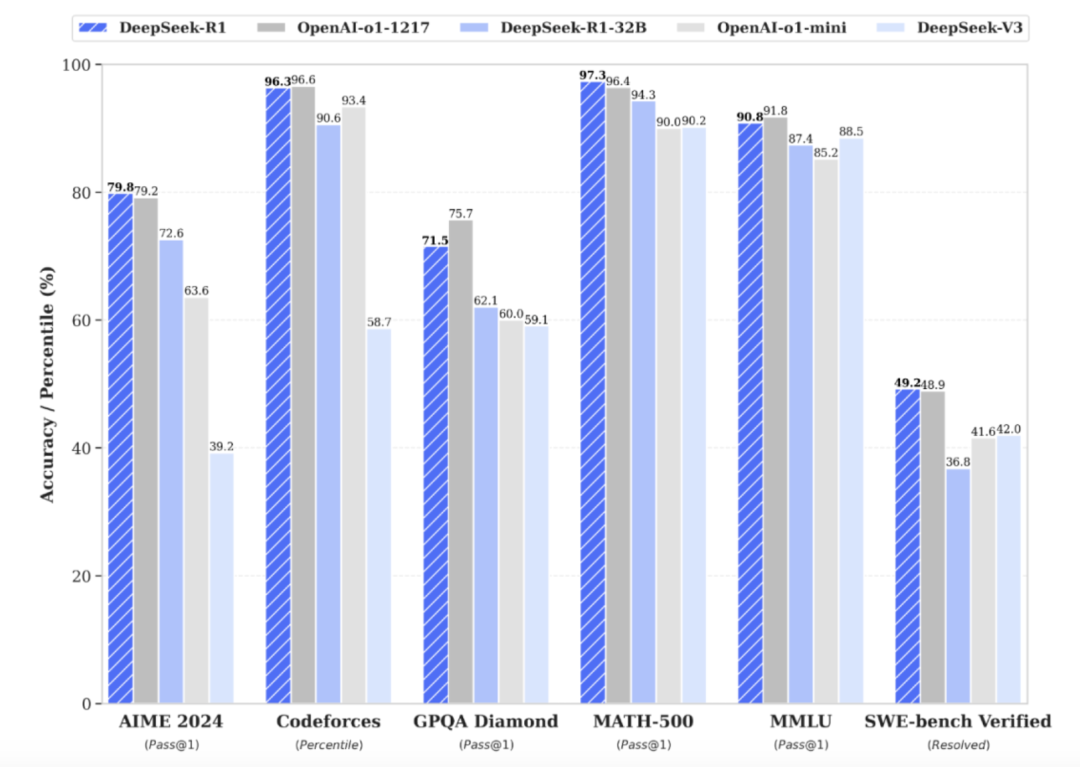
资料来源:DeepSeek官网
DeepSeek-R1打破了“大模型=天价算力”的固有模式,给出了“平民版”模型,让大模型不再只是巨头的游戏。经济日报发文称,DeepSeek技术的突破不仅降低了AI大模型的硬件门槛和能源消耗,更重要的是为AI技术普惠化铺平了道路。因为更小的模型意味着更低的部署成本、更快的响应速度和更广泛的应用场景。在医疗、教育、制造等诸多领域,轻量级AI模型都将带来革命性的转变。 DeepSeek也将推动AI应用和端侧加速繁荣,有望带动AI产业链各细分赛道迎来国产替代机遇。 01 什么是DeepSeek? DeepSeek由国内量化私募领域的巨头幻方量化创立,总部位于杭州。 幻方量化拥有丰富的技术积累和强大的算力资源,作为大厂之外唯一一家储备万张A100芯片的公司,为DeepSeek的技术研发奠定了坚实的基础。 DeepSeek专注于开发先进的大语言模型(LLM)及相关技术,依托自研的训练框架、自建的智算以及万卡算力等资源优势,为模型研发提供硬件支撑;通过大幅度缩减以往大模型所需要的庞大算力,直接把大模型的成本降了下来;其核心团队成员来自清华大学、北京大学、浙江大学等国内顶尖高校。 此外,DeepSeek实施开源策略,全系列模型已经完全开源,并且免费商用,为开发者和企业提供经济实惠的选择。 DeepSeek不断推出新的模型版本,已经相继发布了DeepSeekLLM、DeepSeek-Coder、DeepSeekMath、DeepSeek-VL、DeepSeek-V2、DeepSeek-Coder-V2、DeepSeek-VL2、DeepSeek-V2.5、DeepSeek-V3、DeepSeek-R1系列。 去年12月底,DeepSeek发布的DeepSeek-V3开源基础模型性能,与GPT-4o和ClaudeSonnet3.5等顶尖模型相近,但训练成本极低。整个训练在2048块英伟达H800GPU上完成,仅花费约557.6万美元,不到其他顶尖模型训练成本的十分之一。 1月20日,DeepSeek发布DeepSeek-R1模型,并同步开源模型权重。该模型在后训练阶段大规模应用了强化学习技术,即便是在极少标注数据的情况下,也显著提升了模型的推理能力。
DeepSeek-R1 API 服务定价为每百万输入 tokens 1 元(缓存命中)/ 4 元(缓存未命中),每百万输出 tokens 16 元。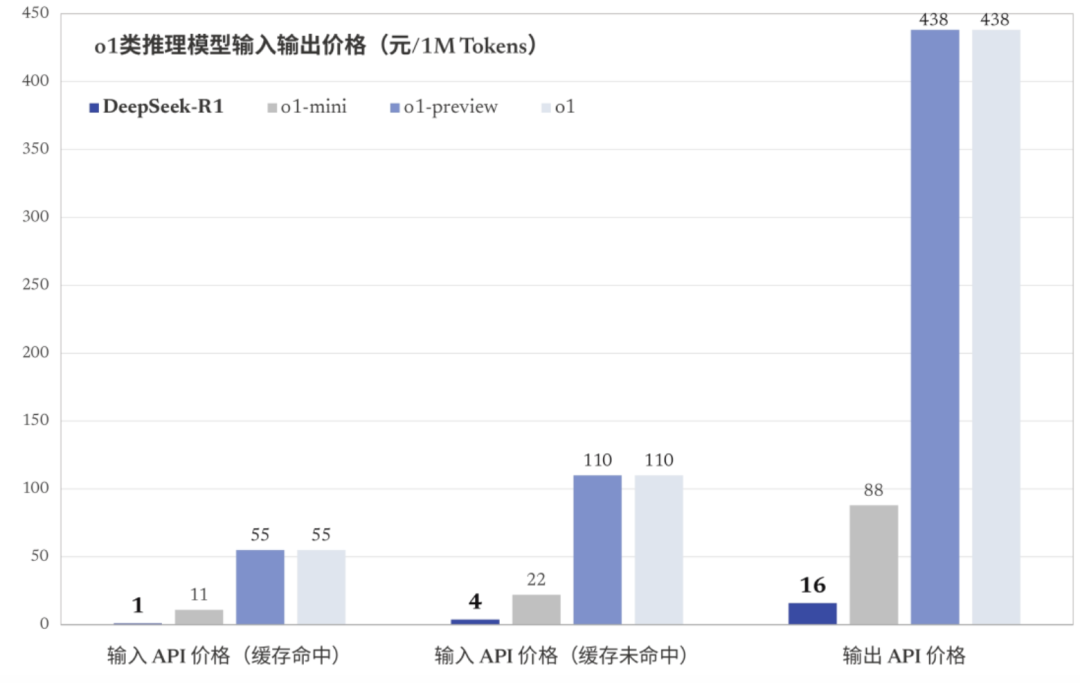
资料来源:DeepSeek官网
1月24日,在专业大模型排名Arena上,DeepSeek-R1基准测试已经升至全类别大模型第三,其中在风格控制类模型(StyleCtrl)分类中与OpenAIo1并列第一。而其竞技场得分达到1357分,略超OpenAIo1的1352分。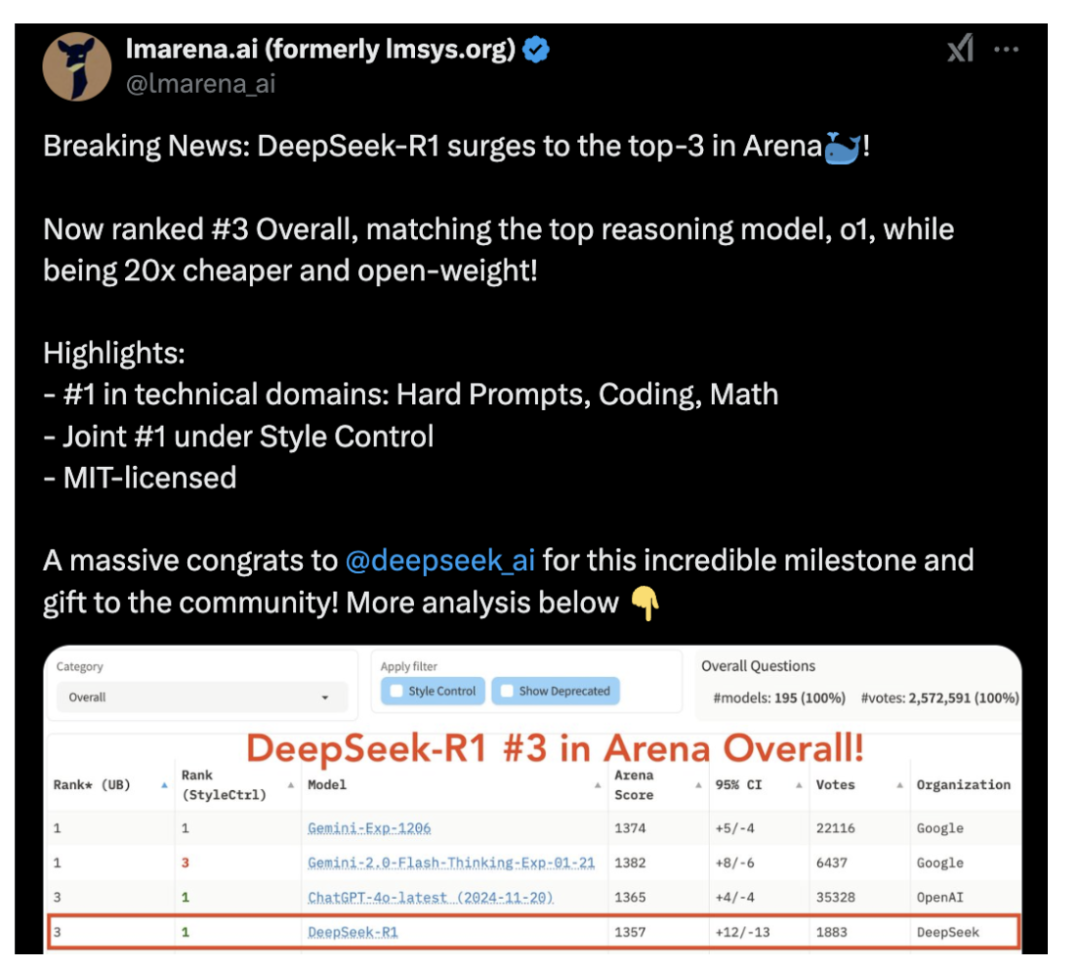
1月24日,A16z合伙人、MistralAI董事会成员AnjneyMidha表示:“从斯坦福到麻省理工,DeepSeek-R1几乎一夜之间成为美国顶尖大学研究人员的首选模型。” 1月25日,AMD宣布,已将新的DeepSeek-V3模型集成到InstinctMI300XGPU上,该模型旨在与SGLang一起实现最佳性能。 有海外用户认为,DeepSeek大模型以极低成本(600万美元)和少量芯片(2000块)实现了与OpenAI等巨头相媲美的性能,挑战了"唯有科技巨头才能研发尖端AI"的行业共识。
02DeepSeek产业链
DeepSeek产业链包括上游算力基础设施、AI芯片等(为AI模型研发训练提供基础支持)、中游模型研发、训练与优化(产业链核心环节,价值占比最高),下游商业应用和技术合作服务等环节 产业链中,AI基础设施、算力、算法、应用等都是值得重点关注的核心环节。
上游算力基础设施算力基建和硬件是AI模型研发与训练的核心基础,对模型的性能表现、运行效率以及成本支出具有重要影响。 DeepSeek创始人、头部量化私募幻方量化创始人梁文锋曾表示,DeepSeek面临的主要制约因素不是资金,而是高端算力的使用权,这些芯片对于训练先进AI模型至关重要。 尽管有人表示,新的DeepSeek成本减少,可以提供同规模的多个大模型。但是当前AI大模型的训练成本仍然居高不下,即便推理效率有所提升,但训练出高效模型依然可能依赖于大规模的计算资源。如果追求更高的模型精度,训练阶段的算力消耗并未必会减少,因此上游的算力需求依然强劲。 同时,下游应用的爆发式增长也将进一步推动算力基础设施的建设和发展。 从供应链的安全性和性价比角度出发,国产算力基础设施的占比有望持续提升,包括服务器、算力芯片、交换机、光模块等多个关键环节。 算力相关文章:1、算力产业链核心赛道:液冷服务器全解析 2、算力产业链核心赛道:高速光模块全景解析 3、算力芯片产业格局全景解析 上游算力环节中,浪潮信息为DeepSeek北京亦庄智算中心提供AI服务器,配备英伟达H800GPU及自研AIStation管理平台;中科曙光承建DeepSeek杭州训练中心液冷系统,单机柜功率密度达35kW,PUE小于1.15,为DeepSeek提供算力支持;润泽科技廊坊数据中心为DeepSeek提供3000+机柜资源,采用间接蒸发冷却技术,运营成本低于同行15%,为DeepSeek提供算力资源;并行科技为DeepSeek提供了多种并行计算技术;寒武纪和景嘉微等国产AI芯片制造商,也将受益于DeepSeek技术推动的算力需求增长。 此外,DeepSeek的AI模型已适配华为昇腾芯片,在适配过程中,DeepSeek解决了芯片不支持某些代码的问题,通过改算法绕开限制,并优化了性能。 每日互动作为幻方量化的二股东,牵头的浙江大数据计算中心为DeepSeek提供算力支持,此外还为DeepSeek提供海量用户行为语料数据,用于模型训练和优化、双方在算法和数据智能领域有深度合作;昆仑万维与新加坡南洋理工大学联合开发的Q算法显著提升了DeepSeek模型的推理能力。例如,在数学领域,Q算法帮助DeepSeek-Math-7b模型在MATH数据集上的准确率提升至55.4%,超越谷歌Gemini Ultra。 中游:模型研发和数据训练
中游模型研发训练是AI产业链的核心环节,直接影响到AI模型的最终性能和效果。
DeepSeek模型由杭州深度求索人工智能基础技术研究有限公司独立研发训练。此外模型研发离不开高质量的数据训练。 AI数据集是大模型训练和测试的基础,数据标注是数据集最核心的环节,贯穿大模型全生命周期。当前AI大模型和智能体持续涌现,高质量和专业化的数据标注成为刚需。 卓创资讯与幻方量化(DeepSeek的母公司)在金融语料库方面存在合作,其数据资源可能被用于DeepSeek模型的训练和优化,为DeepSeek提供专业的金融领域数据支持。 拓尔思政务大数据市占率第一,拥有4000+行业知识库,可快速生成领域微调数据;此外,还与DeepSeek联合开发金融舆情大模型。 此外,该环节相关厂商中,海天瑞声AI训练数据市占率国内第一;法本信息的FarAI人工智能平台包含了自动化数据标注工具;博彦科技为大模型公司提供多种数据类型和标注任务;中科软数据标注平台在医疗领域有相关应用;易华录已经拥有24个数据湖进入运营期,将申报建设国家级数据标注基地;汉王科技获得了发明专利授权“医疗领域标注数据的获取方法、装置、电子设备”;此外包括数据堂、云测数据、龙猫数据、星尘数据等数据标注专业型服务商。 分布式训练框架方面,东方国信CirroData数据库支持大规模分布式训练数据管理,已用于电信运营商AI平台;星环科技SophonLLM工具链提供国产化微调解决方案,适配昇腾和海光硬件。 模型压缩和部署方面,格灵深瞳INT4量化工具可将175B模型压缩至8GB显存需求,边缘部署刚需技术;当虹科技视频压缩技术转用于模型参数传输优化,降低分布式训练通信成本。
下游:AI应用、技术合作与服务
商业化应用和技术合作服务是AI产业链的价值实现环节,关系到AI产品的市场接受度和盈利能力。 DeepSeek模型在教育、医疗、金融等多个领域广泛应用。该领域相关布局厂商中,根据公开资料显示,科大讯飞在教育领域接入DeepSeek-Math模型,联合推出AI数学辅导应用“星火助学”,共同推动AI技术在教育领域的应用落地;金山办公WPS智能写作功能集成DeepSeek-WriterAPI,公文生成效率提升3倍,错误率下降90%,为DeepSeek提供商业化应用场景。 此外,浙江东方通过旗下杭州东方嘉富基金参投DeepSeek天使轮,持股路径为浙江东方→东方嘉富(持股40%)→DeepSeek;华金资本珠海国资旗下投资平台,通过华金领越基金间接参与DeepSeekPre-A轮融资,布局AI大模型赛道。 本月IDC最新发布的报告显示,市场开始进入整合期,其中,“由于商业模式难以为继,基础模型市场将进行整合。到2029年,企业使用的80%基础模型最多由8家供应商提供。” 当前全球AI军备竞赛加速,国内如DeepSeek、月之暗面等人才密度高且具备较强算法和压缩AI算力成本技术能力的厂商有望加速引领国内AI领域的新一轮变革.乐晴智库精选

 公安备案号 51010802001128号
公安备案号 51010802001128号