












-
【国盛通信 · 深度】黎明已经到来——从技术演进看国产算力投资机会
股林 / 12月26日 08:19 发布
摘要
国内算力需求的黎明已经到来。AI爆发两年以来,海外通过前期的算力积累和模型建设,开启了AI的商业循环之路,这对于国内的互联网巨头来说,意味着大规模部署AI业务的前提条件已经具备。今年以来,国内“豆包”、“可灵”等优秀模型也开始商业化尝试,随着头部模型厂商开始走向放量与商业循环,我们认为,对于中国互联网行业蛋糕的再一轮切分即将到来,而在本轮竞争之中,算力的建设,尤其是自主可控的算力建设,将是一切的先决条件。
GPGPU还是ASIC-先解决能用的问题。近期,博通在业绩电话会上描述了未来ASIC芯片的宏伟蓝图,但对于国产算力来说,我们判断,“能用与易用”的GPGPU将是未来几年的主旋律。相较于GPGPU,当下的AIASIC主流路线虽然纸面效率较高,但是在编译器,生态软件上与国内客户需求的适配度较低。从当下来看,随着国内以“豆包”为代表的大模型应用加速放量,各厂商需要的是能够快速部署,抢占业务入口与用户的通用型算力,也就是GPGPU。同时对于以运营商,地方智算的建设者来说,通用算力代表着更好的用户接受度与投资回报率。长期来看,随着中国AI模型的竞争格局逐渐清晰,头部玩家的业务颗粒度逐渐变大,AIASIC也将在中国找到合适的渗透场景。
中国AI通信,路在何方?随着中国算力加速放量,自主可控的AI通信能力建设也迫在眉睫,我们认为,建设中国AI通信,同海外一样,分为“Scale-Out”与“Scale-Up”两个部分。对于以交换机,以太网为主导的“Scale-Out”网络,核心是具备从芯片到整机自主可控的交换机体系。而对于过去更加封闭和专用的“Scale-Up”网络,我们不应走英伟达NV-Link体系的老路,而是应当学习海外以博通、AMD为主导的“UA-Link”联盟的经验,以及博通提倡的从封装开始的算核标准化互联服务,凭借过往中国电信巨头的网络经验和国产交换机芯片,封装技术的革新,组成适用于所有国产算力的自主版“UA-Link”和算核封装标准。
基建与制造:中国算力的底气!AI算力建设发展至今,已经跳脱了单芯片计算能力的范畴,逐渐演变成从能源,通信到的系统性工程。如同航母一样,是对于一个国家综合实力的考量。虽然在地缘政治下,中国的芯片制程和单芯片能力受到限制。但我们认为,在国产算力建设过程中,我们的基建与电子制造能力将是中国算力最重要的底牌之一。从两方面来看,首先是电子制造能力,中国的数通光模块企业在多轮速率迭代周期中逐渐建立了竞争优势。同时随着连接方案多样化,中国的铜模组,光纤光缆,长距离光模块等也将为AI建设添砖加瓦。第二方面,中国拥有全球最先进的电网设施和充足的电力供应,当下美国AI建设受困于电网容量,不得不寻求如DCI,天然气,小型核电等方式,但中国良好的电力基础,将使得国内在IDC扩容方面具有不可替代的优势。
投资建议:计算能力、通信能力、制造能力、基建能力的四大环节核心标的
计算能力:寒武纪-U
通信能力:中兴通讯、盛科通信-U、通富微电
制造能力:新易盛、中际旭创、天孚通信、光迅科技、德科立、华工科技、锐捷网络、菲菱科思、紫光股份
基建能力:润泽科技、光环新网、奥飞数据、英维克、麦格米特
风险提示:AI建设不及预期,国内AI需求不及预期,海外制裁风险


投资要件
本篇报告将从一种路径(芯片路线选择)、两种道路(AI、通信发展道路)、三个板块(芯片、通信、配套)、四种能力(计算、通信、制造、基建)梳理国产算力起量过程中的投资框架与逻辑。
市场对于国内算力芯片的发展路径理解较浅。我们坚定认为,相较于ASIC芯片,GPGPU将是更适合中国当下几年算力市场的产品模式。首先,对于ASIC的定义,市场也较为模糊,我们认为,从国际主流来看,AIASIC是指没有DCU部分,只保留TensorCore,且采用脉动阵列取数法为原理的芯片,即谷歌TPU、Groq、Tenstorrent等海外主流ASIC。其余保留了DCU部分的芯片,均应归类为GPGPU类型。虽然ASIC的芯片,在同等制程和面积下,拥有更高的理论性能,但ASIC芯片的开发,需要编译器和软件生态层面的配合。由于没有DCU部分的辅助,ASIC芯片的编译器开发难度远高于GPGPU芯片,同时新的生态软件也给客户带来了极高的切换成本。因此,在当下阶段,只有从模型训练到推理应用全自有的海外头部大厂,才能较好的运用自研ASIC。
对于国内来说,未来几年是算力部署的初始阶段,GPGPU算力的易用性将使其对客户更有吸引力,中国需要先用海量的,可用且易用的GPGPU算力堆砌出自己的模型与商业循环,在完全成熟以及业务颗粒度放大之后,ASIC在国内的市场才会慢慢显现。
当然在此过程中,对于GPGPU架构的优化也非常重要,例如可以同样通过对DCU中不同算力精度小核的取舍,来强化芯片的AI精度,也就是FP16精度的算力,实现更好的追赶,我们认为这才是对于中国算力来说当下更为合适的道路。
市场对于中国AI通信该如何发展理解较浅。随着AI规模的扩大,自主可控的AI通信,将会变得更加重要。发展自主可控的AI通信,有两个领域,第一是Scale-Out领域,这个领域主要涉及到交换机芯片到整机的自主可控,第二个则是Scale-Up领域,这个从英伟达经验来看,更加封闭且垄断,但我们认为,国内芯片厂商不应该走与英伟达类似的纯自研道路。从海外最新发展来看,从UA-Link联盟的成立,到12月5日博通3.5D封装方案的发布,芯片设计与通信公司的分工正在愈发明确,我们认为,行业应该学习这种趋势,让芯片公司专注于设计,同时集合国内电信巨头的网络经验、封装巨头的技术积累,交换芯片公司的自主产品,从而建立自主可控的由封装到专用芯片再到通信协议的“Scale-Up”网络联盟。
行业催化:
1. 国内模型厂商业务推进加速。
2. 国产算力产品能力不断提升。
投资建议:
计算能力、通信能力、制造能力、基建能力的四大环节核心标的
计算能力:寒武纪-U
通信能力:中兴通讯、盛科通信-U、通富微电
制造能力:新易盛、中际旭创、天孚通信、光迅科技、德科立、华工科技、锐捷网络、菲菱科思、紫光股份
基建能力:润泽科技、光环新网、奥飞数据、英维克、麦格米特
1. 国产算力-能用与易用先行
近期,博通在财报电话会上给出指引,到2027财年,其AI业务的潜在市场规模约为600-900亿美元,我们认为,海外的ASIC的业务版图逐渐浮出水面,这也带动博通市值也一举突破万亿美金大关。
我们将视角拉回国内,许多投资者在这种背景下,认为ASIC作为AI专用芯片,其拥有更强的专用性,在同样的半导体制程下,将会拥有比英伟达为代表的通用GPU更强的理论性能,是实现制程限制下算力“弯道超车”的理想之选。但从当下的客户需求与全球ASIC芯片开发进程来看,我们认为,在未来的2-3年内,GPGPU将依然凭借“能用”与“易用”,成为国产算力的主旋律。
2.1 GPGPU与ASIC的技术对比与优劣分析
为了进一步解释为何我们做出“GPGPU”先行的判断,我们需要从两种芯片的底层技术出发,来理解在进行AI计算时,两种芯片的运算特点,与各自设计,使用场景的优劣。
随着大模型训练需求的跃升,Transformer算法快速风靡,Transformer算法通过大量且单一的“矩阵乘法”运算,使得模型的参数,能力快速跃升,带动了AI的高速发展。这种通过单一,大量的矩阵乘法运算来实现“大力出奇迹”的运算特点,也给当下的芯片演进,带去了不一样的土壤。
(由于技术部分过于复杂,不是此篇报告论证的重点,因此在本篇报告中只做大概论述并给出主要结论,更详细的两者技术对比以及演进路线可以参考我们之前发布的报告《AI算力的ASIC之路——从以太坊矿机说起》)
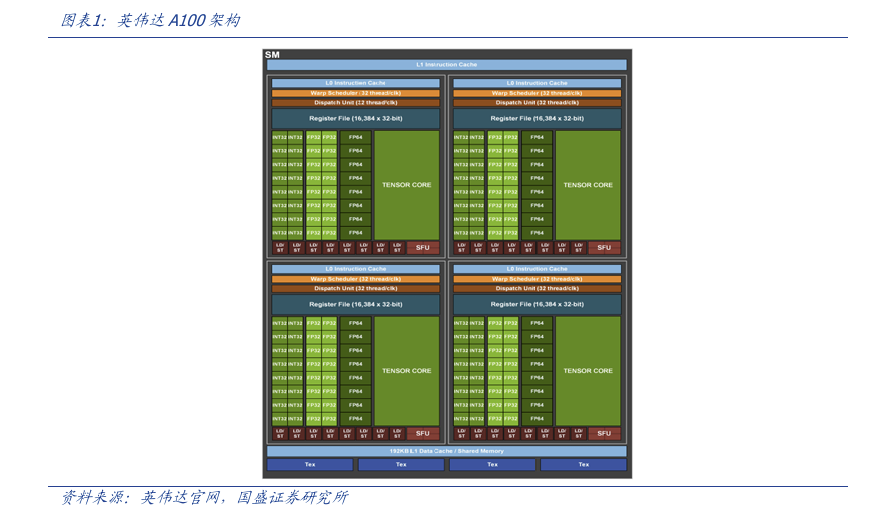
我们先来看以英伟达为代表的GPGPU是如何在芯片微架构层面完成一次矩阵运算的。GPGPU构型的芯片,最大的特点是其芯片由两大部分组成,专门负责矩阵运算的TensorCore(TU)与负责其他运算如向量运算,加减乘除的小核部分(DCU)。
在GPGPU构型的芯片上,进行一次矩阵乘法运算的大体过程如下,DCU中的每一个小核心先从HBM中取出一个单独的数字,将其传送给TU,连续多个cycle后,将TU填满,进行一次矩阵乘法,并得出结果。
在ASIC芯片上,以当下主流的TPU架构为例,其底层原理是“脉动阵列取数法”,从微架构层面看,其抛弃了DCU小核的部分,只保留TU大核来进行矩阵乘法运算。CPU与编译器直接从HBM中取出数字灌入TU来进行运算。
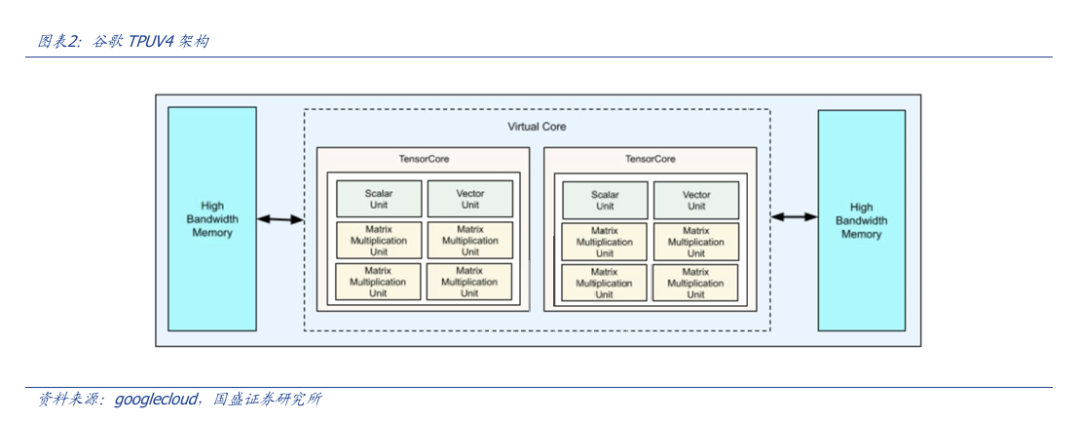
这么做有两个好处,第一,省去了在实际运算中不参与矩阵乘法的“DCU”部分,可以将多余的面积堆积更多的TU,从而实现更高的“AI算力密度”。第二,由于采用了“脉动阵列取数法”作为填满TU的底层原理,其将TU装满运算一次,并得出矩阵乘法结果的速度也更快。两者相互结合,相同面积与制程下,此种原理的芯片相较于英伟达的GPGPU,可以拥有更好的理论算力。
但与之对应的,ASIC的芯片相较于GPGPU也有不少缺陷和劣势。第一,在碰到稀疏数据,数据流中断时,脉动整列取数法的效率会降低,而GPGPU因为有DCU提前处理数据,因此不会有此类隐患。而在AI场景中,大部分数据是稀疏数据,同时受制于通信,显卡所获取的数据并不完全连续,这在一定程度上降低了ASIC芯片的理论效率。
第二,则是ASIC芯片的设计难度,过去我们常常认为,ASIC由于用途单一,设计会更加简单,但进入大模型芯片时代以来,由于大模型运算存在并行计算,数据切分等特点,虽然ASIC的硬件结构较GPGPU更加简单,但是软件编译器层面却成为了一个设计痛点。
我们以美国头部ASIC创业公司Groq为例,由于脉动阵列取数法的特性以及串联工作流的模式,一套计算流程往往需要多个计算核和存储的配合,如何保证这些元器件同时稳定运行,保证计算的确定性,这就需要非常复杂的编译器设计。以Groq为例,其在芯片架构内部,甚至专门增加了用来协调不同计算单元指令流的专用模块,足以见得这项工作之复杂。同时,往后来看,随着Transformer及其变种的持续进化,如何设计出一款优秀的编译器,能够让芯片快速适应新模型以及微调的Transformer算法,将是考验一款ASIC除了架构外最重要的能力。
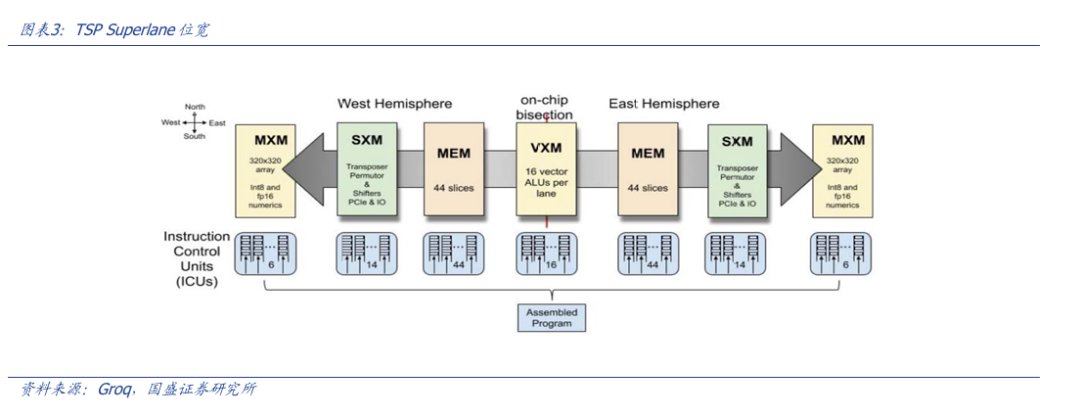
回顾Groq的创业历程,可以看到,初步的硬件架构在2020年的论文中就已完成,后续至今的四年,团队主要专注于相关编译器和软件生态的研发。可谓是两年做硬件,四年完善编译器。由此可见软件的重要性和难度不容小觑。

第三,则是ASIC对于客户来说,拥有更高的学习成本,同样以Groq为例,Groq的软件语言也更加复杂,需要同时对多个功能单元的指令集进行设计,使用时也需要重新学习,这无疑对于新用户上手来说更加困难。

2.2 我们的判断:GPGPU仍将是国内的主旋律
上一节中,我们可以看到,以TPU为代表的主流ASIC,虽然凭借原理的创新在相同的制程和面积下拥有更高的理论性能和性价比,但是其编译器工程量与难度较大,同时对于新用户来说具有非常高的学习成本。因此在北美市场,只有头部互联网大厂成功实现了自有模型与自有ASIC体系的融合,因为其芯片在设计初期,就充分考虑到了针对自身业务的优化,同时随着北美AI业务颗粒度扩大,确定的专用需求空间,也足以支持ASIC的发展费用,这才是ASIC发展的前提条件。
回到国内,国内正处于模型能力快速迭代,互联网厂商正在快速扩充算力争夺客户入口的阶段,同时绝大多数的B端客户仍未能开启AI化进程。同时受制于海外限制,中国无法获得最新算力,因此对于当下的中国互联网客户来说,快速补充能用,易用的国产算力是当务之急,而ASIC则是业务发展到一定成熟阶段后,需要用足够的市场空间和时间来换取长期费用节省的一种思路,对于当下的中国算力市场并不贴合。同时,走ASIC路线的芯片公司,往往需要更长的时间去调试编译器来释放架构的完整性能,在国内制程受到限制的情况下,编译器完成度不高的ASIC芯片,其竞争力和性价比会显著弱于GPGPU架构。
总结来看,由大小核心构成的GPGPU架构,经过英伟达多年积累,对于国产算力厂商来说,无论是全球能够找到的设计人才储备,以及客户对于相关软件环境和使用习惯的积累,都是能更好形成“能用,易用”算力的路径。但这也不代表我们要完全抛弃ASIC之路,在GPGPU构型之上,我们可以同样通过对DCU中不同算力精度小核的取舍,来强化芯片的AI精度,也就是FP16精度的算力,实现更好的追赶。往长期来看,中国芯片厂商,在手机芯片等方面积累的优秀架构,也有凭借ASIC的性价比,再次焕发生机的机会。
3.中国AI通信路在何方?
随着国产算力卡放量以及国内算力建设的加速,如何构建中国自主可控的AI通信体系,也成为了中国算力自主可控的重要一环。
从全球来看,英伟达选择了从显卡,交换机芯片再到通信协议的全自研体系,随着开源以及拥有更高性价比的以太网协议不断追赶,英伟达也开始推出以太网系列产品。在英伟达之外,以AMD为代表的其余的厂商普遍加入了由博通等巨头牵头的通信联盟,UEC超以太网对应IB网络,用于Scale-out,而UA-Link则对标NV-LINK,用于Scale-up。
对于中国厂商来说,当下依旧以海外芯片为主,但是在自主可控的大背景下,我们认为未来的机会将出现在两个方向,第一是以太网交换机芯片的国产替代,第二则是随着国产芯片放量,参与到中国版“NV-LINK”的合作与开发之中。
3.1 中国AI通信之Scale-Out-以太网主导,交换机芯片是核心
从全球来看,在Scale-Out网络这一层面,目前主要是两大协议在相互竞争,一个是英伟达独有的IB协议,另一个则是博通主导的以太网协议。
在AI放量初期,英伟达的IB交换机凭借更好的性能以及对于AI训练的支持独树一帜,但随着在博通带领下的以太网联盟对于ROCE 2.0协议的迅速推广以及调试,性价比更高且开源的以太网开始逐渐渗透。
时至今日,以太网风头更盛,一方面是ASIC芯片的初步放量,使得以太网的用户群体逐步扩大,另一方面,则来自于交换机层面的交付周期。在特斯拉的财报电话会上,马斯克表示,特斯拉的10w卡基于以太网体系构建,而非IB协议。
将视角移回中国AI市场,当下来看,中国的主流交换机厂商推出的AI交换机普遍基于海外芯片。但正如上文提到,交换芯片与调优正逐渐成为决定网络协议胜负和AI网络能力的核心因素。因此,中国自主可控的交换芯片,将成为组建全国产化AI的关键一步,同时通过与国产芯片厂商与客户的紧密合作,国产交换芯片也有望获得更快的渗透曲线。

3.2 中国AI通信之Scale-Up-“中国版NV-Link”迫在眉睫
在Scale-Up网络这一层面,全球目前是NV-Link发展较快,而NV-Link的持续迭代,也是英伟达在GPGPU架构下,保持对于ASIC芯片性能及性价比领先的关键一步。
同时,ASIC和博通为代表的竞争者们,正在从过去的各自为战,转变为统一联盟,24年5月,博通、AMD、Arista、谷歌等芯片,互联网,网络巨头们组成UA-Link联盟,共同创建一种加速器到加速器的开放行业标准化互联,也就是人人可用的“NV-link”。
回顾非英伟达系的Scale-Up网络发展的历史,最早是Intel用于多核CPU服务器之间互联的片上ROCM协议,再到AMD优化后的“InfinityFabric”,随后AMD将这份协议开放给了“思科,博通,Arista”三家网络巨头,再到后来AMD加入UA-Link寻求互联方案。可以看到,在对抗英伟达的NV-Link上,博通为首的厂商,选择了开放,标准化之路,这也符合芯片降本,提升竞争力的目标。
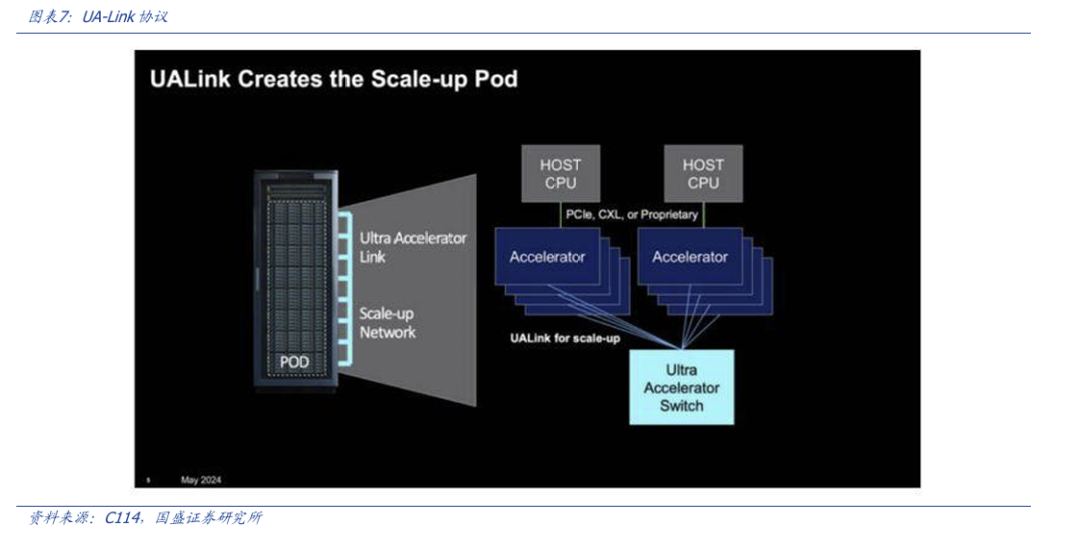
我们把视角拉回到国内,我们认为,海外UA-LINK联盟的成立,给了中国自主可控的“Scale-Up”网络以非常好的追赶机会。对于单一的芯片厂商来说,实现从基于传统Rocm的八卡互联到拥有全套NV-Link协议以及对应专用交换芯片的跨越需要大量的研发投入以及时间成本,这对于处于追赶期的中国芯片公司来说,很难承受。
但对比海外,中国一样拥有具有深厚通信协议经验积累的电信巨头,同样也拥有自主可控交换芯片道路上不断探索的企业,我们认为,如果这些企业能够带头组成类似于“UA-LINK”一样的联盟,可以快速帮助中国芯片公司形成对标“NV-LINK”一样的互联能力,这将助力中国算力的高速发展。

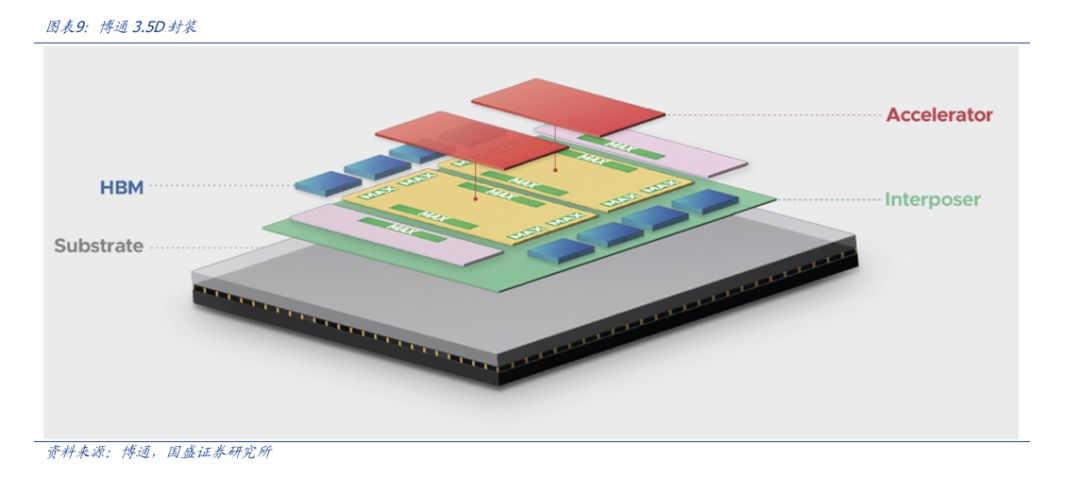
在12月5日,博通发布了下一代的3.5D封装技术,可以使得芯片公司专注于算核的设计,随后将一切算核与HBM,算核与外界通路的互联,打包进3.5D封装方案。从而变成具有极强互联能力的算力卡。我们认为国内也可以借鉴这一趋势,将自主可控的芯片标准延伸至封装设计层面,帮助中国算力更好更快的成长。
4.中国基建与中国制造:中国算力的底气
相比于美国算力的发展,中国由于受制于制程影响,在绝对的芯片性能上受到了较大的限制。进入AI时代以来,单芯片性能固然重要,但算力的部署已经逐渐成为了像航母一样考验一个国家综合制造能力的系统工程。
与美国相比,中国在电子制造业上积累了深厚的产业优势,同时在美国当下最紧缺的电力基础设施方面,中国凭借全球领先的电网以及能源供应,有底气支撑海量的AI算力。
4.1 通信制造业:中国工业的明珠
进入AI时代以来,由于数据中心互联需求的加大,通信速率的迭代周期开始不断加速,光模块需求快速上升。以中际旭创、新易盛、天孚通信为代表的中国厂商,凭借在上一轮云计算浪潮中建立的产业地位和制造优势,迅速成为北美客户光模块的主流选择。
回到国内来看,随着国内算力逐渐放量,国内对于光模块的需求也将逐渐释放,同时叠加在速率迭代下,DAC等传统连接线缆向AEC的升级,也有望助力光模块厂商实现在迈向制造业龙头成长路上的品类扩张的关键步伐。
国内的光模块格局,过去由于市场竞争格局,国内光模块厂商的净利润率普遍偏低,但随着供需格局在算力带领下逐渐改善,我们认为,国内光模块厂商也将受益此轮从市场总体供需到客户结构的改善。
4.2 IDC:再次成为核心资产
前文提到,相较于美国,中国的电力基础设施与容量,都相较美国来说更优。因此,美国的互联网厂商在未来有可能走向自建核电站+DCI互联的扩容之路。我们在最新的深度报告《AI的新视角:从算力之战到能源之争》中详细阐述了基建逻辑。但对于国内来说,完善且充足的电力设施可以让客户通过第三方IDC提供的电力资源和机房实现算力的快速部署,从而为算力抢装和业务扩展提供助力。同时由于不需要新建变电站、核电站等设施,中国的算力成本也有望通过基建和电力侧缩小与海外先进的差距。
5.投资建议
我们认为,投资国产算力放量机会,主要从四个主要能力出发即计算能力、通信能力、制造能力和基建能力。
计算能力:抓住更适合中国当下需求的芯片技术路径,从产品力出发,优选标的。
:寒武纪-U
通信能力:我们认为,未来“Scale-Out”网络主要依靠自主可控的交换机芯片,而“Scale-Up”网络则需要封装、芯片、通信巨头一起组建联盟。
:中兴通讯、盛科通信-U、通富微电
制造能力:中国的通信制造业中,光通信拥有全球领先的产品和制造能力、交换机拥有优秀的成本控制和整机工程能力。
:新易盛、中际旭创、天孚通信、光迅科技、德科立、华工科技、锐捷网络、菲菱科思、紫光股份
基建能力:在中国优秀的电力基建下,IDC公司有望成为AI基建的主要承担方之一,助力互联网厂商快速扩张算力。
:润泽科技、光环新网、奥飞数据、英维克、麦格米特

 公安备案号 51010802001128号
公安备案号 51010802001128号